In un sondaggio commissionato da Confcommercio e pubblicato qualche giorno prima di San Valentino, uno degli appuntamenti del calendario commerciale, si stimava una spesa pro-capite di 85 euro, da destinare più a cene romantiche che all’acquisto di regali (fonte: Ansa). La voce del dato accoglie esercizi a scopo didattico. Non sono dei casi di studio, non potrebbero esserlo, ma degli esempi di scuola. Il tono vorrebbe essere appunto didascalico e l’attenzione più sui processi di analisi, e sugli obiettivi, che sui risultati di ciascun esercizio. L’intento è far conoscere i metodi dell’intelligence applicata al marketing, declinati al modo di tropic: monitorare/ascoltare i messaggi e i comportamenti, pulire i dati, costruire corpora, analizzare il dato grezzo, trasformare i dati in informazioni azionabile, supportare le decisioni e favorire il fine-tuning con le opinioni, i bisogni, le aspettative, le emozioni e le percezioni delle persone.
Questo numero 29 è appunto dedicato a San Valentino. L’esercizio è volto a capire come costruire un’indagine per conoscere quali prodotti sono stati cercati online, e quanto e come si è parlato di quei prodotti.
Prima di incominciare, facciamo come sempre una carrellata sulle pubblicazioni di tropic nei sette giorni che ci separano dall’uscita dello scorso episodio della newsletter. Come sempre, i link valgono come riferimenti bibliografici.
Abbiamo pubblicato il numero 22 di Parole d’Italia e il numero 14 di Share of Words. Sono le due rubriche settimanali di tropic. Se con Parole d’Italia osserviamo un campione casuale di messaggi generati settimanalmente nell’infosfera di lingua italiana, con Share of Words l’analisi del contenuto si allarga a un campione casuale di messaggi generati in una vasta porzione dell’infosfera internazionale.
Questa settimana, Parole d’Italia ha pure ospitato un approfondimento su 5.000 messaggi pubblicati su TikTok.
La piccola demo di questa settimana è dedicata all’esplorazione di alcuni correlati lessicali del concetto di policrisi. Abbiamo sondato circa 164.000 status pubblicati su Facebook dal 2014 al 2024, in cui comparivano le parole paura, angoscia, o timore, e ne abbiamo estratto alcune informazioni.
Infine, abbiamo gettato uno sguardo su alcuni dati relativi al marketing e all’advertising durante il Super Bowl, condividendo i nostri appunti di lettura su audience televisiva, performance social ed efficacia comunicativa degli spot.
Iniziamo ora il piccolo esercizio sui prodotti cercanti online a cavaliere di San Valentino, e sul conversato che quei prodotti hanno generato. Avanziamo un passo alla volta, per cercare di capire come poter ascoltare il mercato, cioè gli attori che lo popolano e che lì si relazionano.
Iniziamo con un’attività di search intelligence. Il bersaglio è la chiave di ricerca “San Valentino”.
In primo luogo, estraiamo qualche informazione relativa alle domande che le persone “fanno” a Google, e proviamo a costruire un piccolo grafo a partire da quei dati. Non è molto grande, ma una piccola pozione dedicata alla ricerca di informazioni correlate in modo immediato al dominio commerciale c’è (in alto, sulla sinistra).
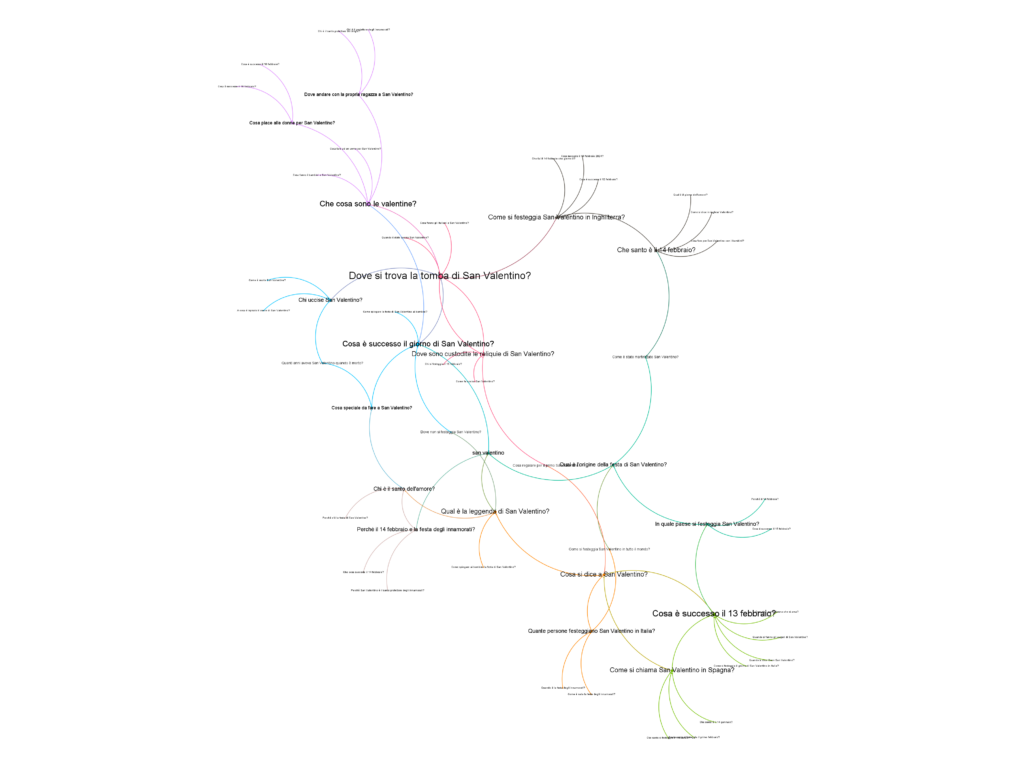
Proseguiamo. Monitoriamo una finestra che precede di 30 giorni il 15 febbraio. Selezionano le related keywords della chiave “San Valentino”; filtriamo 1.500 tra queste.
Cerchiamo qualche traccia che ci possa offrire dei segnali solidi sulle attività commerciali (informazionali o transazionali) relative a San Valentino. La traccia più solida dal punto di vista informazionale è la domanda “cosa fare a San Valentino?”. Dal punto di vista transazionale, invece, troviamo l’espressione “idee regalo”.
Seguiamo questo secondo indizio, e sondiamo la nuova chiave: “idee regalo”
Vediamo quali sono i domini maggiormente premiati dal traffico generato da quella chiave.

Abbiamo dunque un altro indizio. Andiamo a esplorare il dominio più premiato.
Selezioniamo il traffico organico. Poi le chiavi di ricerca non-branded. Tutte le feature della SERP e tutti gli intenti, in modo da poter aver un bouquet più ampio da esplorare per formulare le inferenze.
Partiamo dalle search keywords. E già un mondo si dischiude. Non necessariamente correlato al nostro appuntamento commerciali, certo. Di prodotti però ce ne sono, e anche alcune categorie.

Proseguiamo estraendo prima ed elaborando poi il dato correlato ai popular terms (non branded). Prima da desktop.

Poi da mobile.
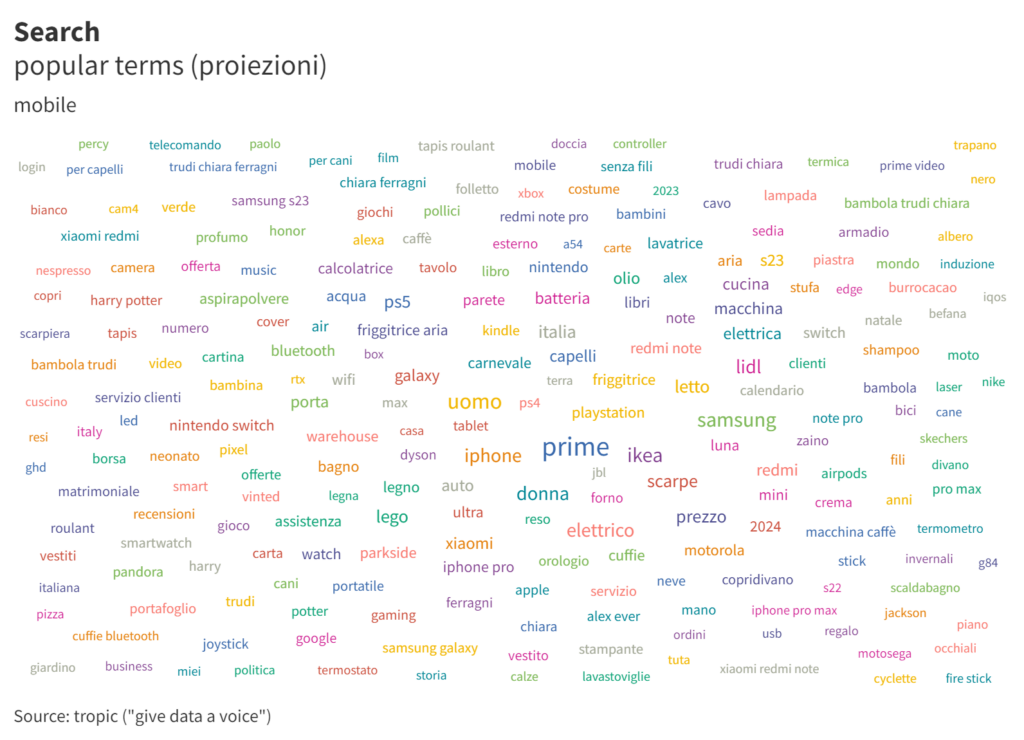
Grazie a questi, i segnali correlati alle categorie, e anche alle azioni, diventano più solidi.
Abbiamo già a questo livello delle informazioni azionabili.
Portiamo ora l’indagine dalle ricerche al parlato. Dai comportamenti alle azioni linguistiche. Puliamo un po’ i dati. Per esempio: filtriamo le chiavi di ricerca e selezioniamo solo quelle non-branded, interpolando lì dove pare necessario (per esempio aggiungendo laptop e notebook). Trasformiamo poi questa lista in una lunga query, che useremo per ampliare l’indagine all’infosfera italiana (social e web) e capire per esempio se nel periodo monitorato c’è stato qualche picco di ricerca.
Vediamo i risultati. Se escludiamo le news (che però compaiono comunque perché sui social ci sono gli account delle fonti giornalistiche, che qui non sono state filtrate), la ricerca ci restituisce 813.000 messaggi, pubblicati da 480.000 fonti uniche.
Vediamo i risultati aggregati. Questo è il trend.
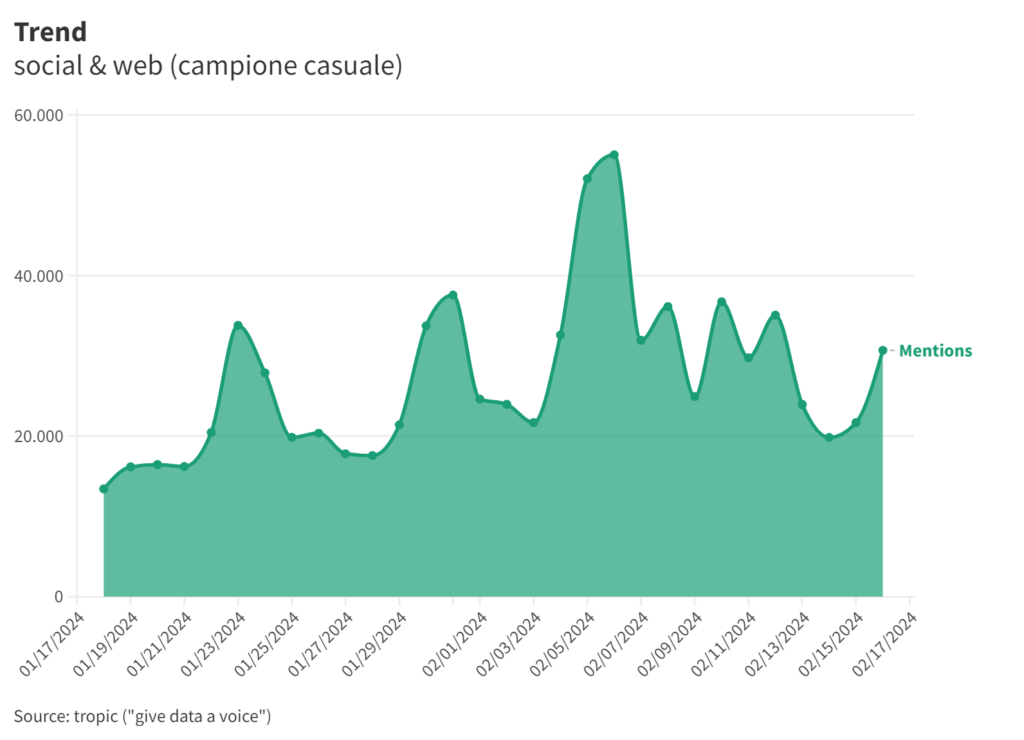
Il picco delle menzioni è il 6 febbraio, non esattamente a ridosso di San Valentino. Ma cerchiamo di contestualizzare. La media giornaliera è pari a circa 27.000 messaggi. Il 6 sono più del doppio, ma sin dal 4 e fino al 12 le menzioni sono superiori a quella cifra. Decrescono invece proprio dal 13 al 15, come si vede nella chart.
Per capire le tendenze nel dettaglio, bisognerebbe ovviamente analizzare ogni singola chiave di ricerca, come si fa negli osservatori. In questo esercizio ci accontentiamo del dato aggregato.
Vediamo ora le parole correlate con maggiore frequenza a quelle chiavi di ricerca, e gli hashtag. Ci sono tanti falsi positivi, le parole-chiave sono generiche e ciò accade.

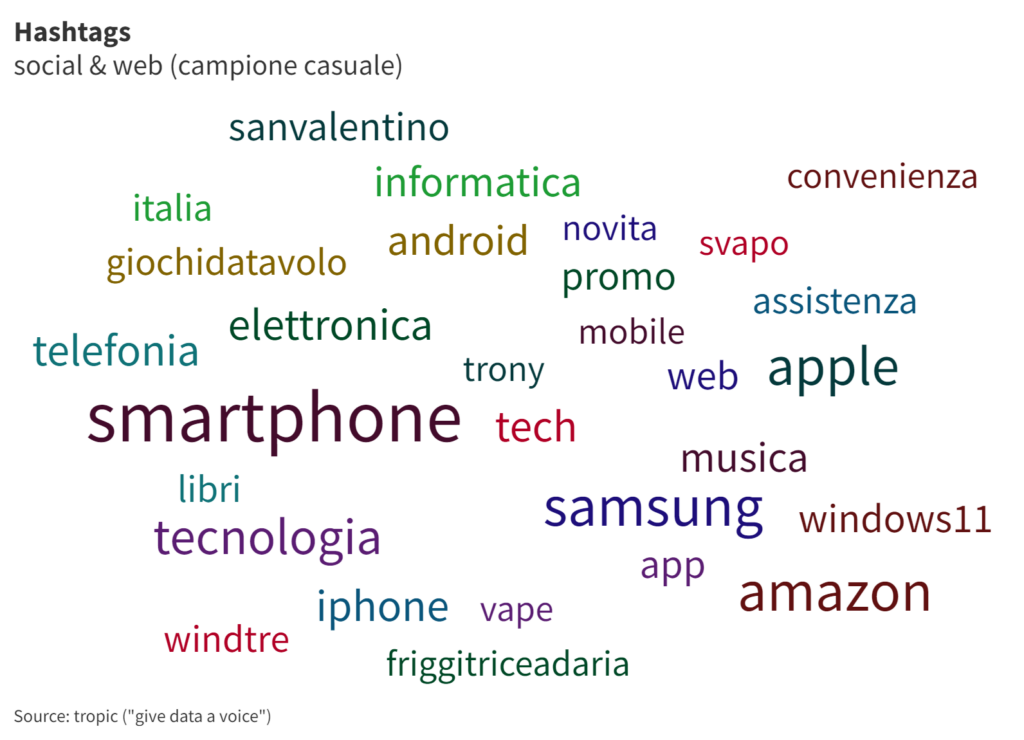
San Valentino, che non era ovviamente presente nella query, non compare tra gli hashtag, ma nelle parole sì. In entrambi i casi, c’è una gerarchia chiara dei prodotti più “chiacchierati”.
Tralasciamo il sentiment, che qui è poco pertinente e dedichiamoci invece a estrarre i 10.000 messaggi, su più di 800.000, che hanno ricevuto più interazioni e proviamo a scoprire quali sono le entità citate con maggiore frequenza.

Qui i prodotti latitano, se si restringe molto la lista, ma compaiono le destinazioni e, come nel caso delle parole, qualche grande attore dell’e-commerce.
Per chiudere. Sottoponiamo quei 10.000 messaggi a un’analisi meccanica per individuare gli argomenti predicati con maggiore frequenza, tra quelli di interesse immediatamente commerciale. Questo è il risultato.

È tutto. Grazie della pazienza e al prossimo episodio.