



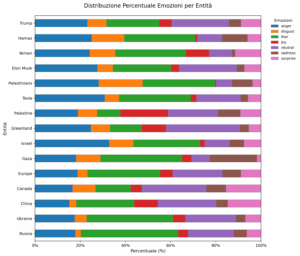
Share of Words (73): i trend settimanali nell’infosfera anglofona
𝗦𝗵𝗮𝗿𝗲 𝗼𝗳 𝗪𝗼𝗿𝗱𝘀 è la rubrica settimanale a cura di tropic srl, che mostra i 𝐭𝐫𝐞𝐧𝐝 dell’𝐢𝐧𝐟𝐨𝐬𝐟𝐞𝐫𝐚 di lingua inglese. Un’attività di content intelligence e
Parole d’Italia (81): i trend della settimana nell’infosfera italiana
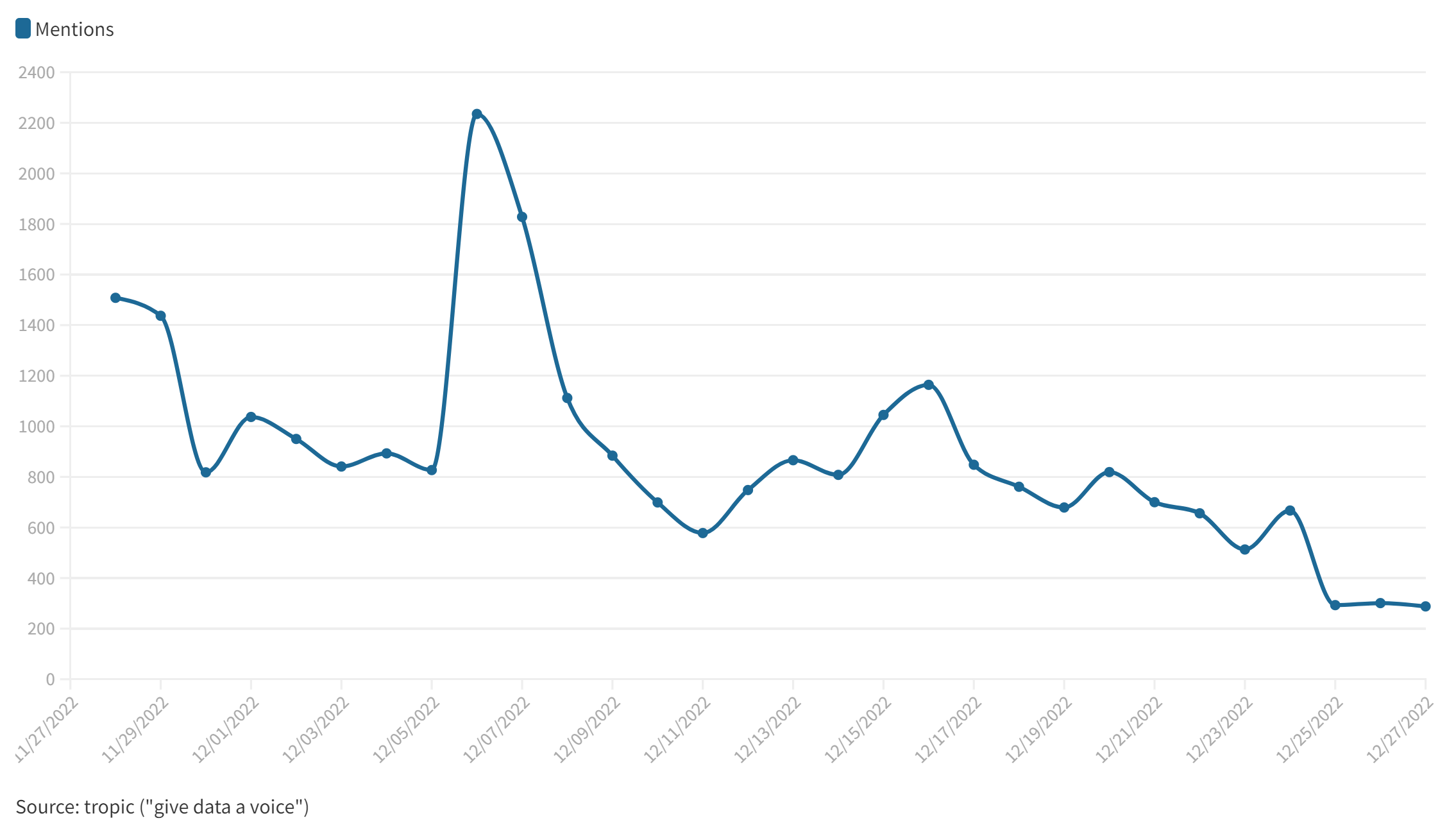
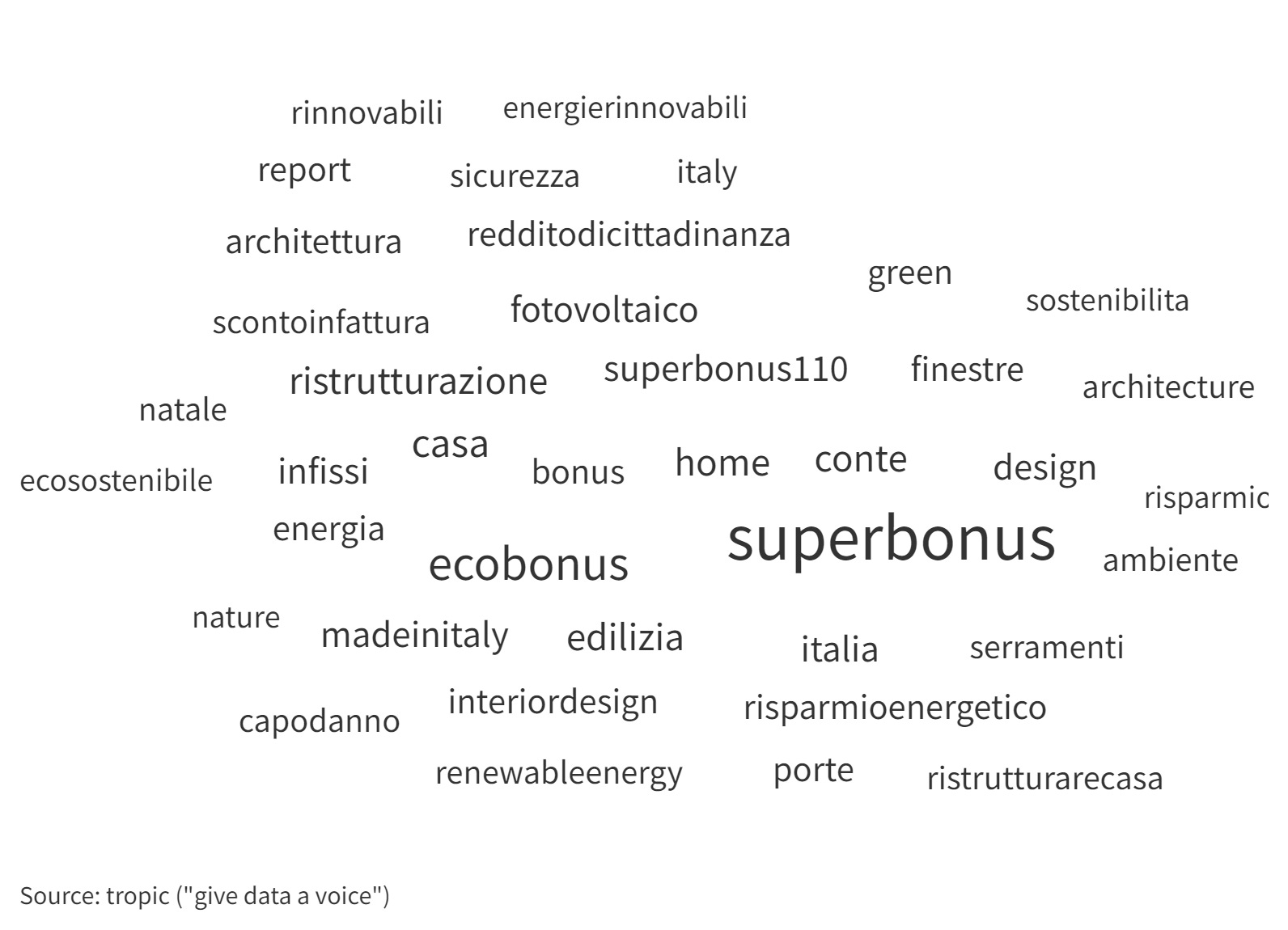
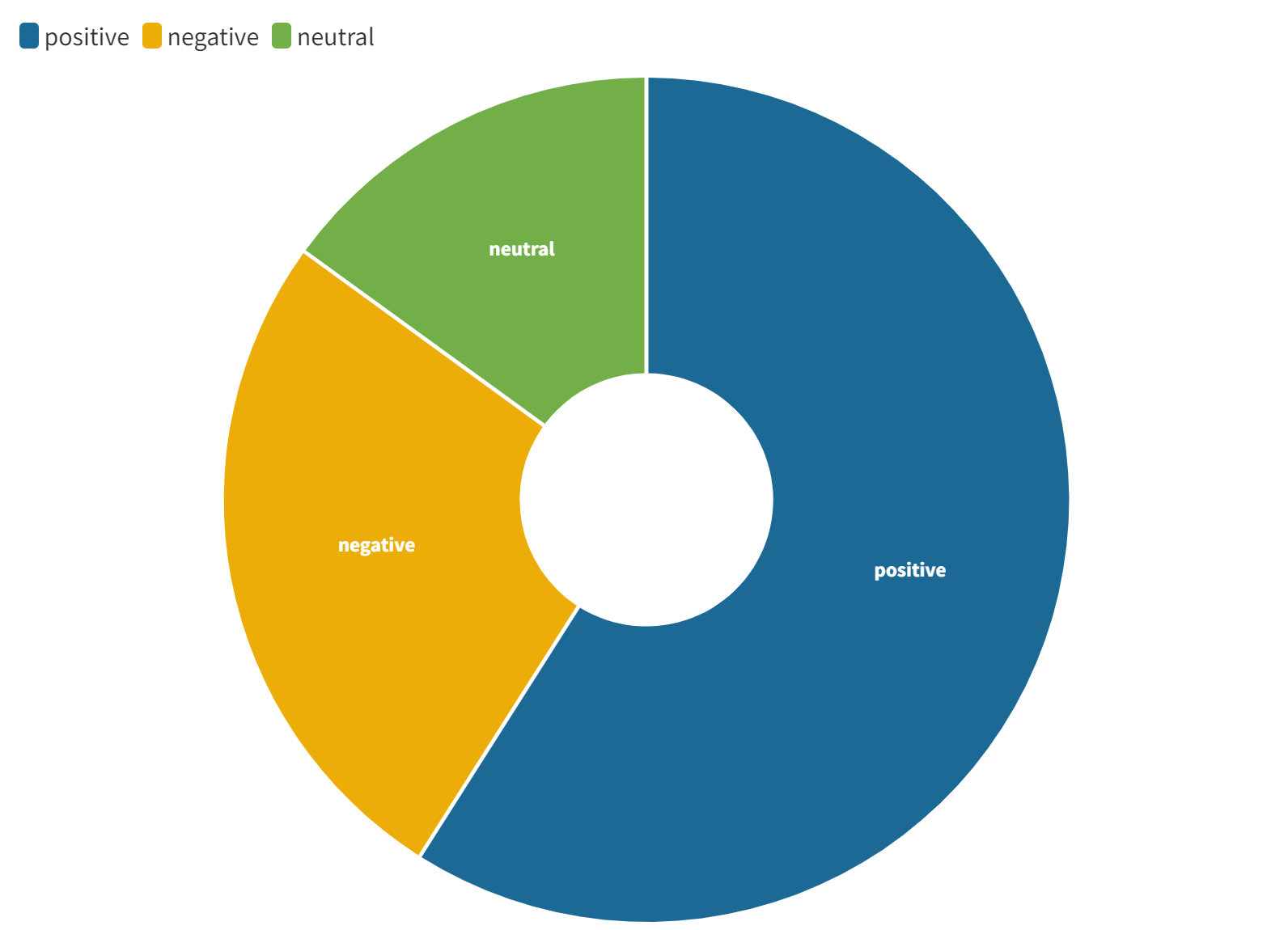
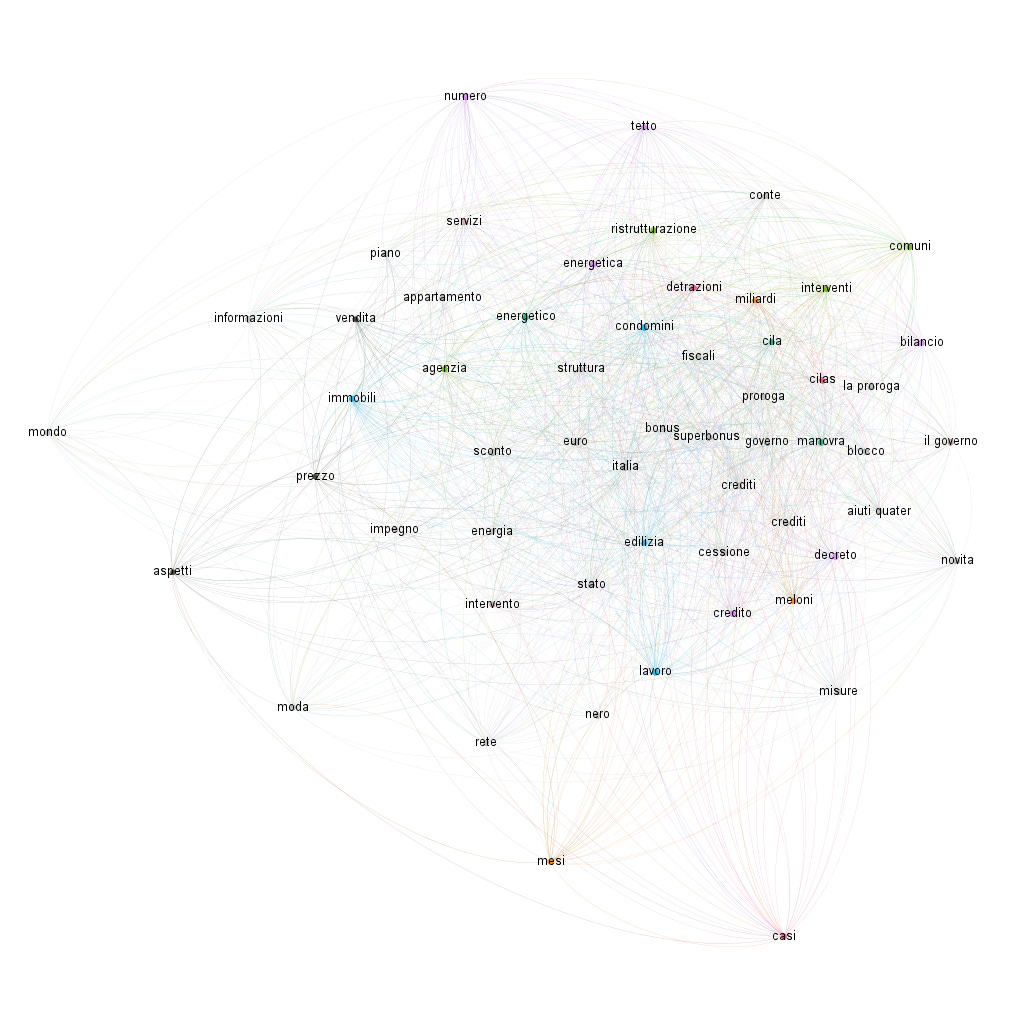
Il monitoraggio dei trend settimanali nell’infosfera italiana, a cura di tropic srl. La settimana monitorata: dal 24 al 30 marzo 2025. 📌9 milioni di messaggi

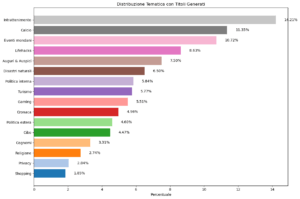
Parole d’Italia (81): le news più commentate della settimana in Italia
Il paragrafo dedicato alle news della rubrica settimanale di media intelligence e opinion mining a cura di tropic srl : Parole d’Italia. Ci sono i
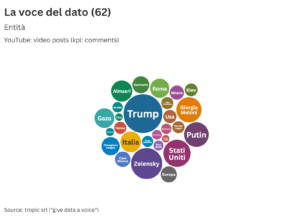
La voce del dato (62) – Il primo trimestre del 2025 della sezione dedicata alle news di Parole d’Italia
1. La voce del dato n° 62 Questo è il numero 62 de La voce del dato, la newsletter di tropic srl. Un’edizione che dà
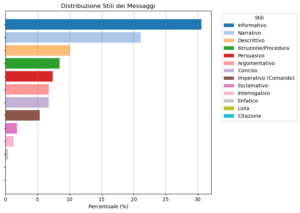
Share of Words (72): i trend settimanali nell’infosfera anglofona
𝗦𝗵𝗮𝗿𝗲 𝗼𝗳 𝗪𝗼𝗿𝗱𝘀 è la rubrica settimanale a cura di tropic srl, che mostra i 𝐭𝐫𝐞𝐧𝐝 dell’𝐢𝐧𝐟𝐨𝐬𝐟𝐞𝐫𝐚 di lingua inglese. Un’attività di content intelligence e
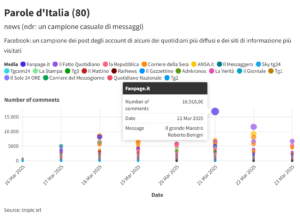
Parole d’Italia (80): le news più commentate della settimana in Italia
Il paragrafo dedicato alle news della rubrica settimanale di media intelligence e opinion mining a cura di tropic srl : Parole d’Italia. Ci sono i